Retrieval-Augmented Generation (RAG) pipelines are AI systems that provide answers to users’ questions. These tools use large language models to retrieve information and process the findings to provide more accurate responses based on factual data.
However, building RAG pipelines is difficult—especially if you need high accuracy. This post covers what a RAG pipeline is, where basic approaches struggle, and four strategies we found to materially improve accuracy, with results. We then explain why a modular RAG architecture is crucial.
What is RAG Pipeline?
Retrieval-augmented generation pipelines let you get more accurate answers than a single large language model can produce. They typically include at least two LLM components: one that retrieves information from data sources such as files or databases, and another that generates the final answer using the retrieved context.
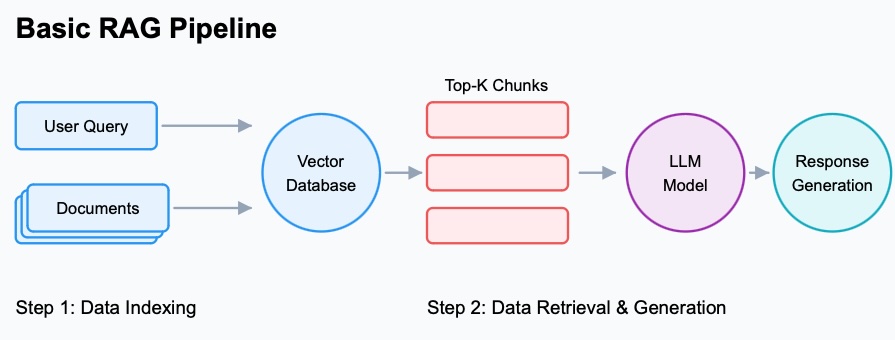 Basic RAG pipeline diagram
Basic RAG pipeline diagram
Basic RAG pipeline components explained
- User query submission: The user writes a query (a prompt) to start the process.
- Query preprocessing: The user’s query is embedded (converted to vectors) so models can understand meaning and relationships.
- Data processing: Data from PDFs, documents, spreadsheets, and databases is extracted, embedded, and stored in a vector database. Source metadata is attached for referencing and faster retrieval.
- Retriever: Takes the query embedding and retrieves relevant chunks from vector DBs or other sources.
- Generator: Turns the most relevant chunks into a human-readable response.
Advanced RAG systems add pre- and/or post-processing steps around retrieval and generation to further improve accuracy.
Issues With the Basic RAG Pipeline
Basic RAG-retrieve some context and let a generator answer-sounds straightforward. Achieving high accuracy isn’t, because:
- LLMs tend to hallucinate.
- Different scenarios require different strategies.
- Many frameworks don’t work “out of the box” for real data and need custom development.
- Many tools are one-way solutions; you can’t easily swap parts to meet your requirements.
Building Advanced RAG Pipelines
Knowing that pre/post-processing can improve results, we asked harder questions:
- Can we have the AI reformulate the user’s question so retrieval works better?
- Can the AI add useful context to chunks so the generator understands them better?
- Should we chunk files page-by-page or otherwise differently to increase accuracy?
After extensive testing, four strategies consistently increased accuracy:
1) Improved Prompt
Many users don’t know how to ask questions for AI systems. We let the AI rewrite queries (query expansion/reformulation) based on the corpus, so the retriever and generator see a better-structured prompt.
2) Contextual Summarization
Before indexing, we preprocess documents by letting models summarize and attach these summaries to the original chunks. Combined with smart chunking, this lifts downstream accuracy.
Producing a good summary requires care; context matters. See: Why LLMs can be terrible at summarizing (LinkedIn)
3) Hybrid Retrieval with BM25
Naive embedding-only retrieval can miss exact terms (e.g., error codes). We combine:
- BM25 (a TF-IDF-style ranking with saturation)
- Semantic vectors (dense embeddings)
At query time we fuse results via Reciprocal Rank Fusion (RRF) and pass them to the generator.
- Background on BM25: Using BM25 to Optimize Answer-Question & Search Tools Accuracy
4) Re-ranking
- Bi-encoders (typical embedding models) produce embeddings and can re-rank via cosine similarity.
- Cross-encoders don’t produce embeddings; they score query-chunk pairs directly and are often stronger rerankers, though they add overhead.
Cross-encoders vs. bi-encoders: see, e.g., Sentence-BERT (arXiv)
Embedding background: Embedding Models Explained
The Result
We benchmarked three configurations:
| Metric | Embedding-only | Hybrid (BM25) | Hybrid (BM25) + Reranker |
|---|---|---|---|
| Retrieval R@4 | 0.7725 | 0.7750 | 0.8585 |
| Answers EM | 0.4360 | 0.4570 | 0.5120 |
| Answers F1 | 0.5584 | 0.5816 | 0.6342 |
| Answers Precision | 0.5909 | 0.6161 | 0.6680 |
| Answers Recall | 0.5604 | 0.5837 | 0.6377 |
These results show the strength of hybrid retrieval and re-ranking. That said, effectiveness depends on your domain and data:
- Semantic search understands relationships but may miss exact matches.
- Keyword search (BM25) excels at exact matches but lacks semantics.
- Query expansion captures related concepts but can introduce noise.
- Re-ranking is powerful for top-k ordering, but cross-encoders add compute overhead.
- Context summarization makes data more understandable to the LLM, but summaries must preserve the right context.
There is no one-size-fits-all.
Why a Modular RAG Architecture Becomes Crucial
We built a modular RAG architecture so you can:
- Mix and match retrieval and generation techniques.
- Configure each component independently.
- Add new techniques as the ecosystem evolves.
- Evaluate combinations automatically.
You shouldn’t have to assemble infrastructure from scratch. Point your data sources to a DKG and integrate via API, and focus on building world-class product experiences.
- Learn more: AI Platform
Conclusion
Advanced RAG pipelines retrieve from your data to deliver more accurate answers-but the right design is domain-specific. You need the flexibility to adjust query reformulation, chunking, summarization, retrieval, fusion, and re-ranking. Our modular approach enables that flexibility and, in our testing, outperforms basic RAG.