Best Match 25 (BM25) is a ranking function that measures query word frequency in relation to document length to produce a relevance score. Search engines, enterprise search, and answer-question tools use it to retrieve the most relevant data and provide more accurate answers.
This article explains how BM25 works, details the algorithm’s components, outlines its strengths and limitations, and shows how we use BM25 inside our systems. At the end you’ll find results from our experiments and context on when to fuse BM25 with other techniques.
What is BM25 (Best Match 25)?
BM25 (also known as Okapi BM25) is a ranking algorithm used to score how relevant a document (D) is to a query (Q). It underpins many search engines, RAG pipelines, and enterprise retrieval systems.
How does BM25 work?
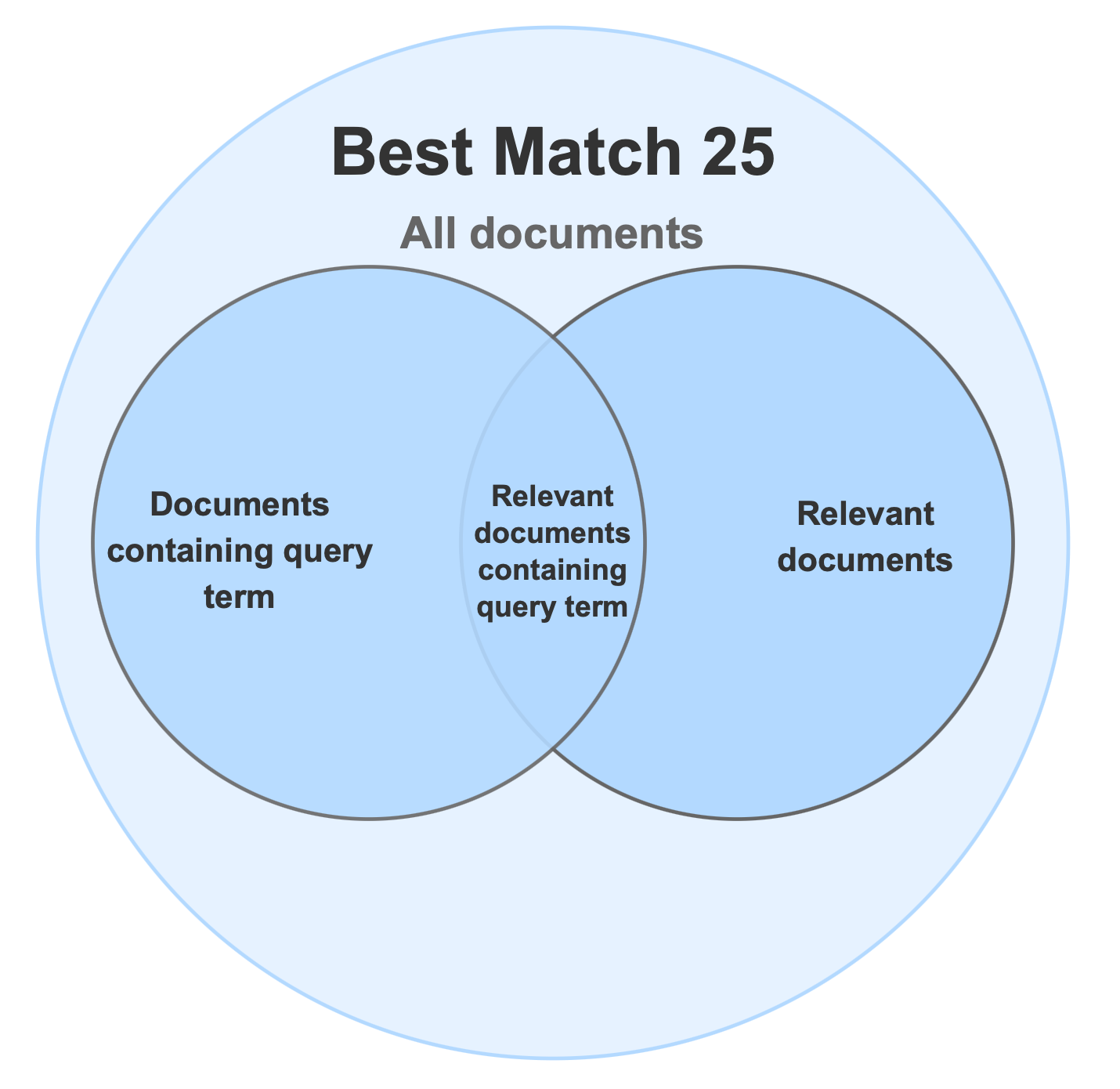
At a high level, BM25 compares the terms in the query to the terms in a document and adjusts for document length. Conceptually, it answers:
- What is the query?
- How many times do the query terms appear in each document?
- How long is each document?
BM25 algorithm
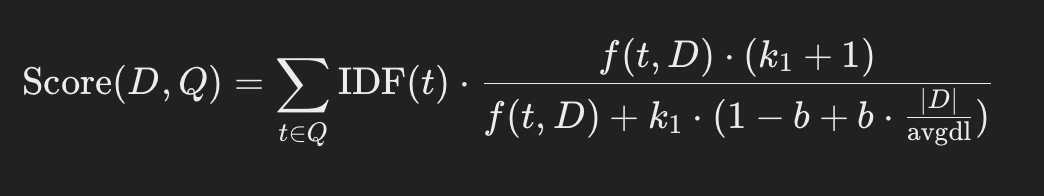
Key components:
- Query terms (t \in Q): The user’s query is tokenized into terms.
- Inverse Document Frequency (IDF(t)): Weighs rarer terms more than common ones (e.g., “the”, “and” contribute little).
- Term frequency (f(t, D)): How often a term appears in the document.
- Document length (|D|): Used to normalize for the fact that longer documents naturally contain more occurrences.
- Average document length (\text{avgdl}): Corpus-level baseline for the normalization.
- Hyperparameter (k_1): Controls term frequency saturation (typical range (1.2!-!2.0)).
- Hyperparameter (b): Controls strength of length normalization ((b=0) no normalization; (b=1) full normalization; commonly (b\approx0.75)).
Advantages and disadvantages
Advantages
- Dynamic ranking: Scores adapt per-query rather than being fixed.
- Length normalization: Prevents long documents from being unfairly favored.
- Customizable: Tune (k_1) and (b) for your domain.
- Widely applicable: Effective across e-commerce, media, enterprise, and more.
Disadvantages
- No semantic understanding: Pure lexical matching; it doesn’t “know” meanings or synonyms.
- No personalization: Treats all users the same unless you add personalization elsewhere.
Where is BM25 used?
- Elasticsearch: BM25 is the default scoring algorithm.
- Web search engines: Google, Bing, and others rely on BM25-style lexical signals among many features.
- Enterprise search: Retrieve from emails, notes, ERP/CRM, wikis, etc.
- E-commerce: Rank products by lexical relevance to the query (often with additional signals).
- Recommendation surfaces: Used as a lexical retrieval stage before re-ranking.
- ConfidentialMind answer-question systems: We combine BM25 with embeddings and other components to improve accuracy.
How we use BM25 in practice
Naive semantic encoding of text chunks can lose exact-term granularity (e.g., error codes, IDs). To mitigate this, in our GraphRAG solution we index chunks twice:
- Semantic vectors (dense embeddings)
- TF-IDF/BM25 (lexical)
At query time we fuse results with Reciprocal Rank Fusion (RRF) and feed the combined set to the generator model.
Precision depends on the chosen top-k, so for evaluation we focused on retrieval recall and answer metrics (EM/F1/Precision/Recall). Following Anthropic’s guidance, we typically retrieve 10–20 items; we used k=10 on HotpotQA (Q/D ≈ 2.0), and increased query size to 1000 because naive RAG is fast.
While HotpotQA’s design (two golden docs among a large corpus) means BM25 isn’t expected to dominate, our goal was to ensure hybrid retrieval doesn’t degrade performance and to observe gains when adding re-ranking.
Results
| Metric | Embedding-only | Hybrid (BM25) |
|---|---|---|
| Retrieval R@4 | 0.7725 | 0.7750 |
| Answers EM | 0.4360 | 0.4570 |
| Answers F1 | 0.5584 | 0.5816 |
| Answers Precision | 0.5909 | 0.6161 |
| Answers Recall | 0.5604 | 0.5837 |
As expected, gains from hybrid retrieval alone are modest on HotpotQA. For what happens when we add a re-ranker to the RAG pipeline, see: ➡︎ Building Advanced RAG Pipelines For High Accuracy Output
Conclusion
BM25 can significantly improve the lexical relevance of search and Q&A systems. It’s especially strong for exact-match queries (codes, IDs, names) and as a first-stage retriever in hybrid pipelines. Combine BM25 with semantic embeddings, query expansion, and re-ranking to maximize downstream answer quality.